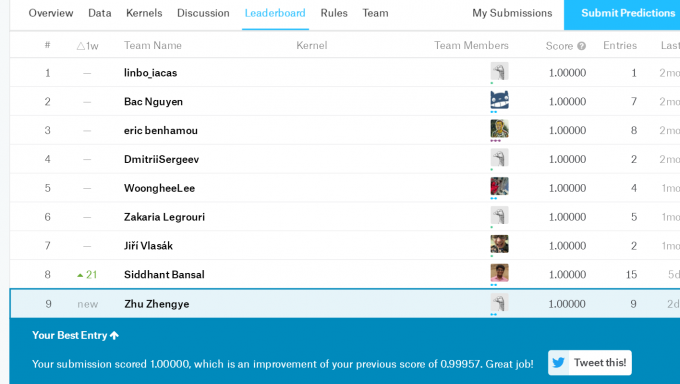
MNIST可以说是深度学习领域的“Helloworld”了,而kaggle上面正好有这样的项目Digit Recognizer,于是就拿这个熟悉卷积神经网络的搭建了。
下面是基于Keras的实现代码(文件路径请修改,参数可以微调)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100import numpy as np
import tensorflow as tf
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense, Activation, Conv2D
from keras.layers import MaxPool2D, Flatten, Dropout, ZeroPadding2D, BatchNormalization
from keras.utils import np_utils
import keras
from keras.models import save_model, load_model
from keras.models import Model
df = pd.read_csv('c:/Users/80431/Desktop/mnist_train.csv')
data = df.as_matrix()
df = None
roundnum=5
for x in range(roundnum):
#打乱顺序
np.random.shuffle(data)
x_train = data[:,1:]
x_train = x_train.reshape(data.shape[0],28,28,1).astype('float32')
x_train = x_train/255
y_train = np_utils.to_categorical(data[:,0],10).astype('float32')
batch_size = 1024
n_filter = 32
pool_size = (2,2)
cnn_net = Sequential()
cnn_net.add(Conv2D(32, kernel_size = (3,3), strides = (1,1),input_shape = (28,28,1)))
cnn_net.add(Activation('relu'))
cnn_net.add(BatchNormalization(epsilon = 1e-6, axis = 1))
cnn_net.add(MaxPool2D(pool_size = pool_size))
cnn_net.add(ZeroPadding2D((1,1)))
cnn_net.add(Conv2D(48, kernel_size = (3,3)))
cnn_net.add(Activation('relu'))
cnn_net.add(BatchNormalization(epsilon = 1e-6, axis = 1))
cnn_net.add(MaxPool2D(pool_size = pool_size))
cnn_net.add(ZeroPadding2D((1,1)))
cnn_net.add(Conv2D(64, kernel_size = (2,2)))
cnn_net.add(Activation('relu'))
cnn_net.add(BatchNormalization(epsilon = 1e-6, axis = 1))
cnn_net.add(MaxPool2D(pool_size = pool_size))
cnn_net.add(Dropout(0.25))
cnn_net.add(Flatten())
cnn_net.add(Dense(3168))
cnn_net.add(Activation('relu'))
cnn_net.add(Dense(10))
cnn_net.add(Activation('softmax'))
cnn_net.summary()
cnn_net.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
cnn_net = load_model('d:/kaggle/digit/cnn_net_model2.h5')
print('开始训练')
cnn_net.fit(x_train,y_train,batch_size=batch_size,epochs=5,verbose=1,validation_split=0.1)
print('训练结束')
cnn_net.save('d:/kaggle/digit/cnn_net_model2.h5')
cnn_net = load_model('d:/kaggle/digit/cnn_net_model2.h5')
df = pd.read_csv('d:/kaggle/digit/test.csv')
x_valid = df.values.astype('float32')
n_valid = x_valid.shape[0]
x_valid = x_valid.reshape(n_valid,28,28,1)
x_valid = x_valid/255
y_pred = cnn_net.predict_classes(x_valid,batch_size=32,verbose=1)
np.savetxt('d:/kaggle/digit/DeepConvNN2.csv',np.c_[range(1,len(y_pred)+1),y_pred],delimiter=',',header='ImageId,Label',comments='',fmt='%d')
看完你也许会问,这么水的一个简单CNN,怎么可能准确度100%?
确实,若是直接训练了再预测,只能拿到0.994左右(排名前20%)。
于是我想神经网络很依赖于大数据,那么怎么再给它更多的呢?
第一,是可以扩展数据,比如翻转缩放等操作后继续喂进去。
第二,嘿嘿,直接用MNIST的官方数据!

这四个全下载并解压,然后转成两个csv,方法可见:MNIST数据集转化为CSV格式
然后其实那10000个test数据带有标签,也是可以用来训练的,于是又想到把这两个合成一个7w行的csv,然后用这个数据替代kaggl的数据训练!
果然,训练了几十次,再去预测,准确率达到了100%!

